RGPD et IA côté web : anonymisation, consentement granulaire et gouvernance des prompts
Introduire l’IA dans une application web ne se résume pas à brancher une API de modèle. Dès qu’un prompt peut contenir des PII (emails, IBAN, numéros de téléphone, NIR), le RGPD impose une rigueur accrue: minimisation, consentement explicite et gouvernance. Ce guide propose des pratiques concrètes pour anonymiser les données, gérer la résidence et la souveraineté, appliquer des politiques de masquage (redaction) et tracer les prompts sensibles — sans répéter nos articles techniques sur Symfony et le temps réel.
Pourquoi RGPD et IA demandent une approche spécifique côté web
Les flux IA diffèrent des traitements “classiques”:
- Les prompts agrègent souvent des données provenant du navigateur, de journaux et d’outils de support.
- Les modèles et vecteurs peuvent être hébergés hors UE si on n’y prend pas garde.
- Le contenu est semi-structuré, ce qui complique la détection/masquage des PII.
Les obligations clés:
- Minimisation: n’envoyer au modèle que le strict nécessaire.
- Pseudonymisation/anonymisation: réduire le risque de réidentification.
- Consentement granulaire: explicite par finalité (assistance, personnalisation, entraînement).
- Résidence et transferts: localisation, clauses contractuelles, DPA.
- Traçabilité et audit: qui a envoyé quoi, où, quand, et avec quelles protections.
Objectif: industrialiser ces exigences dans votre pipeline de prompts, pas au cas par cas.
Anonymisation, pseudonymisation et minimisation: savoir choisir
- Anonymisation: irréversible; impossible de remonter à la personne. Rarement applicable telle quelle dans les prompts, mais utile en analytics.
- Pseudonymisation: réversible sous contrôle; remplace les PII par des tokens. Bon compromis pour le contexte IA.
- Minimisation: supprimer les champs non essentiels avant tout envoi.
Exemples concrets:
- Remplacer les emails par des hachés HMAC salés côté serveur.
- Tokeniser les identifiants (user_123 → usr_tok_8f2c…).
- Purger les colonnes inutiles d’un extrait CRM avant résumé par le modèle.
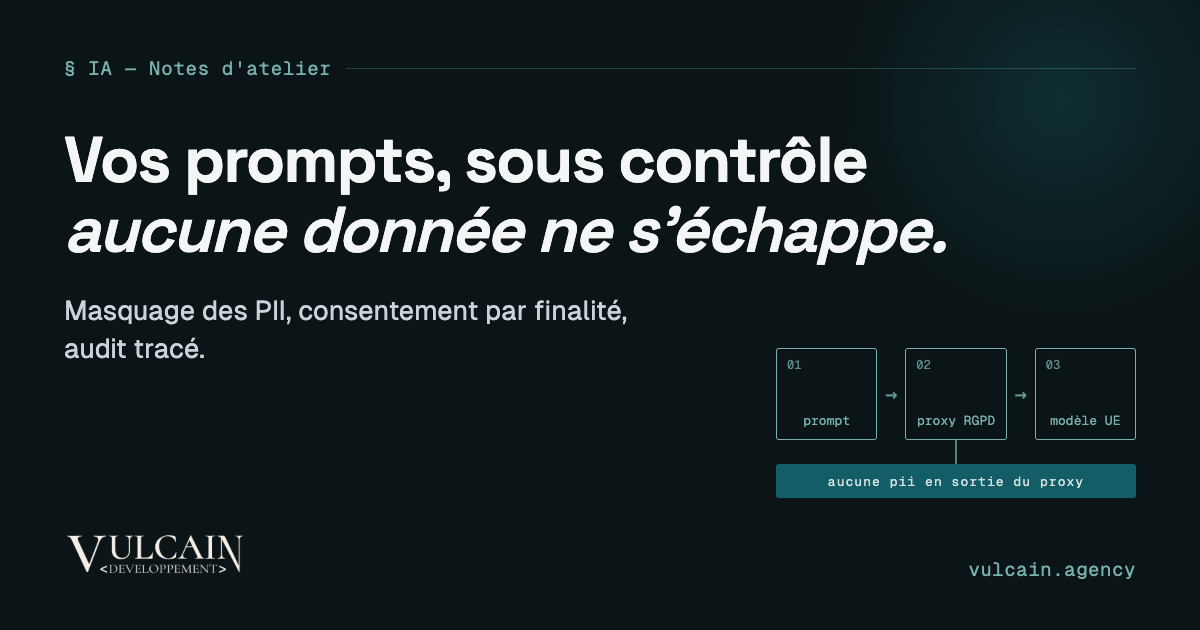
Un pipeline de masquage (redaction) côté serveur
Appliquez la détection et le masquage AVANT tout appel au modèle, dans un proxy serveur, jamais dans le navigateur.
<?php
// src/Privacy/PromptRedactor.php
final class PromptRedactor
{
public function redact(string $input): array {
$detected = [];
// Email
$input = preg_replace_callback('/[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,}/i', function($m) use (&$detected){
$detected[] = 'email';
return '[EMAIL_MASKED]';
}, $input);
// Téléphone FR (simplifié)
$input = preg_replace_callback('/(\+33|0)[1-9](\d{2}){4}/', function($m) use (&$detected){
$detected[] = 'phone';
return '[PHONE_MASKED]';
}, $input);
// IBAN FR (simplifié)
$input = preg_replace_callback('/FR\d{12,27}/', function($m) use (&$detected){
$detected[] = 'iban';
return '[IBAN_MASKED]';
}, $input);
// NIR (sécurité sociale FR) très simplifié
$input = preg_replace_callback('/\b[12]\d{2}\d{2}\d{2}\d{3}\d{3}\d{2}\b/', function($m) use (&$detected){
$detected[] = 'nir';
return '[NIR_MASKED]';
}, $input);
return ['text' => $input, 'pii' => array_unique($detected)];
}
}
- Combinez regex + NER pour réduire les faux négatifs.
- Tenez un registre de versions de politiques (ex: strict-eu-2025-01) pour audit.
- Appliquez la même logique aux documents injectés (RAG) et aux métadonnées.
Consentement granulaire: design fonctionnel et exécution technique
Le consentement pour l’IA doit distinguer les finalités, par exemple:
- Assistance IA dans l’interface (chat, reformulation).
- Personnalisation via IA (recommandations).
- Réutilisation des données pour entraîner/ajuster un modèle.
- Partage avec un fournisseur tiers hors UE.
Exemple de modèle de données pour le consentement
CREATE TABLE user_consent (
user_id UUID NOT NULL,
purpose TEXT NOT NULL, -- ai_assistance | personalization | training | third_party
granted BOOLEAN NOT NULL,
scope TEXT, -- ex: "support", "billing"
recorded_at TIMESTAMP NOT NULL DEFAULT NOW(),
PRIMARY KEY (user_id, purpose)
);
- Interprétez le consentement côté serveur (pas seulement via cookie banner).
- Mappez chaque fonctionnalité IA à un ou plusieurs purposes.
- Dégradez la fonctionnalité si un purpose est refusé (ex. suggestions locales sans appel externe).
Appliquer le consentement dans le pipeline IA
function callModel(array $ctx, string $prompt): string {
$consents = getUserConsents($ctx['user_id']); // depuis user_consent
if (!$consents['ai_assistance']) {
throw new \RuntimeException('Consentement requis pour l’assistance IA.');
}
if (!$consents['third_party']) {
// Force un modèle on-prem / EU-only
$ctx['provider'] = 'local-llm:eu-only';
}
// Masquer si training=false
$ctx['log_retention_days'] = $consents['training'] ? 90 : 0;
$redacted = (new PromptRedactor())->redact($prompt);
return sendToModel($ctx, $redacted['text']);
}
- Affichez une interface de préférences claire et réversible.
- Versionnez les textes juridiques associés au consentement.
- Tracez la preuve de consentement (horodatage, version du texte).
Résidence des données et souveraineté: éviter les transferts non maîtrisés
Points de contrôle:
- Choix de région: privilégiez des endpoints UE (ex. “eu-west-1”) et attestez-le dans vos logs.
- DPA et clauses: signez un DPA avec vos fournisseurs IA, documentez les sous-traitants.
- BYOK/KMS: chiffrez les données et vecteurs avec des clés contrôlées par vous.
- Évitez les captures client->fournisseur directes: passez par un proxy serveur pour appliquer masquage et consentement.
- Pour le RAG, index vecteurs en UE (hébergement et sauvegardes).
Architecture conseillée (schéma logique):
Browser
-> Backend (Privacy Proxy: consent + redaction + policy)
-> EU Model Endpoint / On-prem LLM
-> EU Vector Store
-> Audit Log (EU, immuable, rétention maîtrisée)
Gouvernance des prompts: versioning, politiques et traçabilité
Traitez les prompts comme du code:
- Versionnez les templates de prompt (git + tags).
- Associez chaque requête à une version de template, une politique de masquage et un provider.
- Évaluez le risque (type de PII, finalité, destination).
Exemple de log d’audit structuré
{
"prompt_id": "pr_01J5A8...",
"user_id": "usr_123",
"template_version": "v3.2",
"policy": "strict-eu-2025-01",
"pii_detected": ["email", "iban"],
"consent": {"ai_assistance": true, "training": false, "third_party": true},
"provider": "gpt-4o-mini",
"region": "eu-west-1",
"scope": "support",
"risk_score": 72,
"retention_days": 30,
"timestamp": "2025-09-10T10:35:12Z"
}
Bonnes pratiques:
- Stockage immuable (WORM) avec durée de rétention configurable.
- Export SIEM pour détection d’anomalies (ex. volume inhabituel de PII).
- Accès restreint (RBAC) et justification d’accès (JIT).
Politiques “as code”
Formalisez les règles de conformité en code pour éviter les écarts:
- OPA/Rego ou équivalent pour exprimer: “interdire les NIR vers un provider non UE”, “masquage strict obligatoire pour le scope billing”.
- Tests automatisés sur vos prompts avant déploiement.
Exemple (pseudo-Rego):
deny[msg] {
input.provider_region != "eu"
input.pii_detected[_] == "nir"
msg = "NIR interdit hors UE"
}
Sécurité opérationnelle: du secret management aux journaux
- Secret management: stockez clés API et sel HMAC dans un coffre (KMS, Vault), rotation régulière.
- Journaux applicatifs: ne logguez jamais les prompts bruts; logguez des traces redacted.
- Erreur et observabilité: nettoyez les payloads envoyés à vos outils (Sentry, APM).
- Contrôles d’accès: combinez attributs et politiques pour limiter l’interface IA aux rôles autorisés.
- Tests de régression de confidentialité: intégrez des prompts “canari” contenant des PII factices et vérifiez qu’elles sont masquées.
Plan d’implémentation en 10 étapes
- Cartographier les flux IA et classifier les données (publiques, internes, PII, sensibles).
- Définir les finalités et la matrice de consentement (UI + backend).
- Sélectionner les providers/regions (EU-first), signer les DPA.
- Mettre en place le privacy proxy côté serveur (masquage + consent).
- Versionner les prompts et les politiques de masquage.
- Implémenter les logs d’audit structurés et la rétention.
- Chiffrer au repos et en transit, BYOK si possible.
- Durcir l’accès aux journaux et aux modèles (RBAC, JIT).
- Automatiser les tests de conformité (policy-as-code).
- Réaliser et documenter une AIPD/DPIA pour les traitements IA.
Exemples utiles côté web
- Formulaires: désactivez l’autocomplete sur les champs sensibles si vous alimentez un prompt.
- Téléchargements (RAG): prévisualisez ce qui sera injecté et indiquez clairement la politique de masquage.
- Chat IA: badge “Données EU” + lien “Gérer mes préférences”. Offrez un mode “off the record” sans conservation.
- Back-office: filtrez la recherche IA sur des indices non sensibles si le consentement n’est pas donné.
- Qualification de leads: le pattern EU-first complet est appliqué dans notre agent IA de qualification de leads hébergé en UE — enrichissement et scoring sans qu’aucune donnée prospect ne quitte l’Union.
Conclusion: faites de la conformité un accélérateur, pas un frein
Une IA fiable côté web repose sur trois piliers: minimiser et masquer les PII, prouver le consentement par finalité, et gouverner chaque prompt avec traçabilité. En industrialisant ces mécanismes (privacy proxy, policies as code, logs structurés), vous réduisez les risques juridiques, gagnez la confiance des utilisateurs et facilitez les audits.
Vous voulez auditer votre pipeline IA ou mettre en place un privacy proxy prêt pour la production? Contactez-nous pour un workshop “RGPD & IA côté web” et repartez avec une feuille de route concrète, des exemples de code et des contrôles prêts à déployer.
Ce sujet vous concerne ?
Si cette note fait écho à un chantier en cours chez vous, parlons-en. 30 minutes, gratuit et sans engagement : vous repartez avec 3 recommandations concrètes pour votre projet.